
Customers across different industries and verticals are adopting VMware Cloud on AWS for their production workloads.
If you have workloads that you’d like to run with high availability requirements, it’s important to understand the different architectural patterns and configuration options available.
In this post, we will explain key resiliency design considerations and responsibilities for customers leveraging VMware Cloud on AWS.
At Amazon Web Services (AWS), the Shared Responsibility Model is often referred to when discussing security. VMware’s Shared Responsibility Model for VMware Cloud on AWS is similar, and you can find more details in the VMware documentation.
The diagram in Figure 1 below shows the foundational blocks of VMware Cloud on AWS, and you can see how customers can configure resiliency at each layer:
- Infrastructure resiliency
- Virtual machine and data resiliency
- Resiliency with native services integration
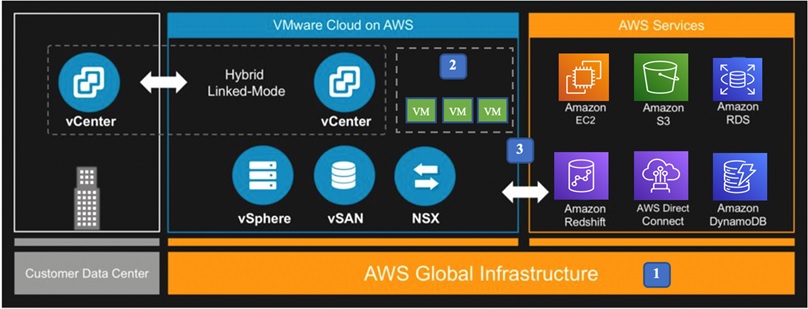
Figure 1 – Foundational blocks.
Infrastructure Resiliency
With VMware Cloud on AWS running on top of the AWS Global Infrastructure and managed by VMware, customers no longer have to worry about the undifferentiated heavy lifting of infrastructure hardware and software maintenance.
AWS and VMware are responsible for the infrastructure and underlying software, and the configuration of the Software‑Defined Data Center (SDDC). Learn more about the Infrastructure Service Level Agreement provided by VMware.
Customer Responsibility
Hardware failures and data center outages can happen, but there are solutions available that can help you automatically failover. Customers are responsible for leveraging these and the built-in capabilities of SDDC to protect their business-critical workloads against regional and data center failures.
Next, we will discuss cluster resiliency options that include stretched and non-stretched clusters, as well as the different connectivity options to your SDDC and resiliency considerations customers should be aware of.
Standard Cluster Resiliency
A standard (non-stretched) SDDC is one in which all hosts are deployed within a single AWS Availability Zone. VMware vSphere High Availability (HA) protects a standard cluster from underlying host failure.
SDDCs with more than one node provide data redundancy through various configurations of Redundant Array of Inexpensive Disk (RAID) along with Failure to Tolerate (FTT), which defines the number of host and device failures that a virtual machine (VM) can tolerate.
You can choose to have no data redundancy (RAID-0), or select a RAID configuration optimized for either performance (Mirroring) or capacity (Erasure Coding).
- RAID 1 (mirroring) offers excellent read speed and a write speed that’s comparable to that of a single storage device. In case a storage device fails, data does not have to be rebuilt but it is simply copied to the replacement drive. The main disadvantage is the effective storage capacity is only half the total drive capacity because all data gets written twice.
. - RAID-5/6 (erasure coding) read operations are very fast, while write data transactions are somewhat slower (due to the parity that must be calculated). If a storage device fails, you still have access to all data, even while the failed storage device is being replaced and the storage controller rebuilds the data on the new storage device. Drive failures influences throughput, although this is still acceptable for most workloads.
VMware Cloud on AWS leverages AWS Partition Placement Groups (PPG) for host placement within a cluster.
When hosts in a cluster are placed in separate partitions, a failure (such as a hardware failure) impacts a single host instead of multiple hosts in a cluster. The VMware Cloud on AWS service delivers this capability automatically and transparently without additional configuration effort.
With PPG and an appropriate FTT configured, you can protect your workloads from rack-level failures.
Virtual machines with FTT = 0 (no data redundancy) may experience data loss if there’s a host failure. Any VMs running with this configuration may become unresponsive.
With a standard cluster configuration and VMware vSAN FTT policy set to 1 or greater, your application workload will have resiliency against host or host component failures in a given Availability Zone.
When scaling clusters up from five to six hosts, the failure tolerance for the underlying policy must be to sustain a minimum of 2 failures (either RAID-6 or RAID-1) to compensate for the larger failure pool.
Clusters using the managed storage policy will be reconfigured automatically, but you must manually update any custom policies. Continued use of policies with FTT-1 for clusters of six or more hosts means VMware will not guarantee availability per the service definition guidance.
Stretched Cluster
For workloads where infrastructure availability is key, we recommend configuring a “stretched cluster” which is a multi-Availability Zone deployment where data is synchronously replicated to hosts in a different Availability Zone.
This option provides your SDDC with an extra layer of resiliency. To prevent data loss, customers should use Dual Site Mirroring Site Disaster Tolerance.
Learn more about stretched clusters in the VMware documentation.
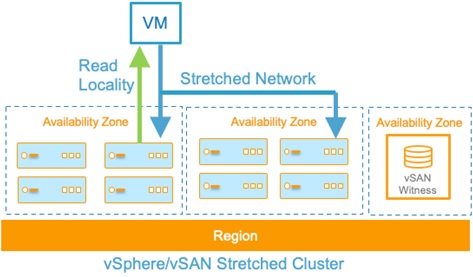
Figure 2 – vSAN stretched cluster.
In the event of an Availability Zone failure, vSphere HA will restart your workloads on the hosts in the other Availability Zone.
Connectivity Resilience for VMware Cloud on AWS
Highly resilient, fault-tolerant network connections are key to application workload availability. Depending on your requirements, you should provision sufficient network capacity to ensure the failure of one network connection does not overwhelm and degrade redundant connections. Let’s take a look at a few options.
Basic Connectivity
IPsec VPN: For basic connectivity with a virtual private network (VPN), IPsec VPNs are the most economical option as it utilizes an internet connection. To avoid a single point of failure, you should use more than one Internet Service Provider (ISP) provider if you want to avoid single point of failure. You are responsible for keeping change records of their IPsec VPN connectivity parameters.
Dedicated Connectivity
AWS Direct Connect: We recommend you configure VMware Cloud on AWS to use AWS Direct Connect when you expect to have more than 1Gbps sustained traffic between the workloads in your SDDC and on-premises environment, or require consistent performance for your traffic.
Direct Connect with VPN as Backup: You can choose to have AWS Direct Connect as your primary connection option and IPSec VPN as backup. Please refer to the following blog post on Simplifying Network Connectivity with VMware Cloud on AWS and AWS Direct Connect.
VPNs do not provide the same high speed, low latency, and consistent network performance as AWS Direct Connect. You should avoid relying on VPN as backup for workloads and connections that are greater than 1Gbps.
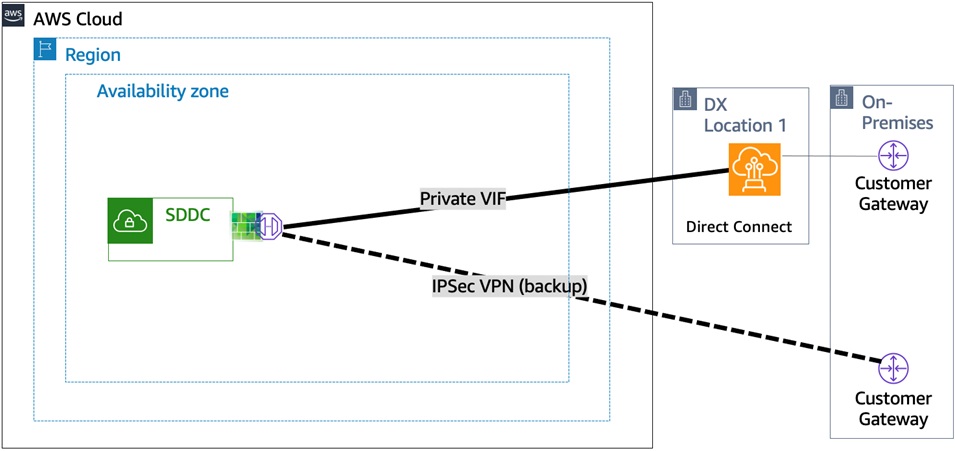
Figure 3 – AWS Direct Connect with VPN as a backup.
Dual VIF to SDDC Over Redundant Direct Connect Connections: For all production workloads, the recommended configuration is to have at least two virtual interfaces over separate physical Direct Connect connections terminating at different Direct Connect locations (location redundancy). Learn more about AWS Direct Connect best practices.
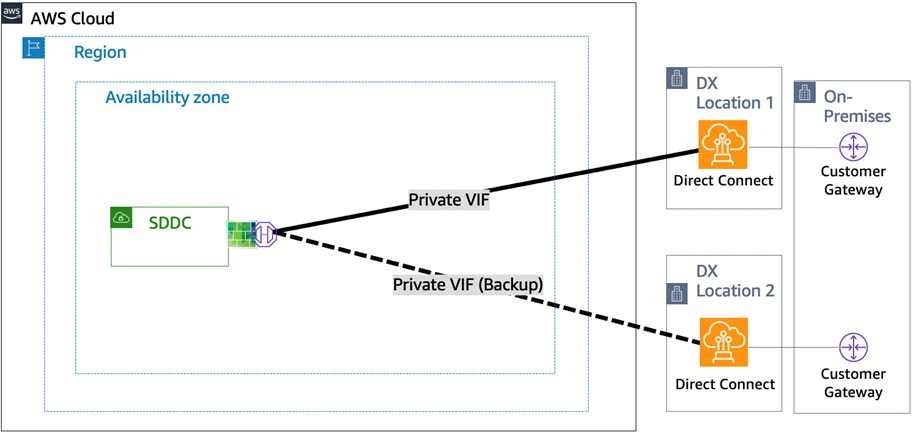
Figure 4 – Dual VIF’s over redundant connections.
Connectivity to other Amazon Virtual Private Cloud (VPC) instances from your SDDC can be achieved using AWS Transit Gateway, VMware Transit Connect, AWS Direct Connect gateway, and VPN connections. It’s your responsibility to ensure redundant network paths are configured to support failover when a network connection fails to maintain availability.
Virtual Machine and Data Resiliency
VMware Cloud on AWS provides two vSAN datastores in each SDDC cluster: WorkloadDatastore, managed by the Cloud Administrator, and vsanDatastore, managed by VMware as described in the documentation.
Customer Responsibility
Infrastructure backups (vCenter and NSX) are done daily, and customers should be aware there are no options for granular or point-in-time restores of infrastructure components or configurations. Any additions or changes to items the customer has configuration access to (such as network segments, VPNs, firewall or NAT rules) will not be backed up until the following day.
You are responsible for ensuring these change details are captured, such as in a change log, architecture diagrams, and internal change control process. You can also use the VMware Cloud on AWS API Reference and the Programming the VMware the VMware Cloud on AWS document, which uses REST programming interfaces to capture changes, store and restore them if needed.
You are responsibile for ensuring the contents of the WorkloadDatastore, including the policies and configurations, are backed up, tested, and stored in a location outside of the SDDC.
It’s important to refer to your requirements, where you may need to consider multiple versions or copies of your data to facilitate point in time restores. One way to minimize costs in VMware Cloud on AWS is to store your backups on Amazon Simple Storage Service (Amazon S3) using an AWS Storage Gateway or other storage appliance using a partner-integrated solution or application-level backup software.
The Storage Gateway on-premises securely transfers the backup data to the Storage Gateway backend using AWS Direct Connect or through an SSL internet connection.
AWS File Gateway uses an AWS Identity and Access Management (IAM) role to access the customer backup data and securely store it in Amazon S3.
VM snapshots offer the ability to roll back after a change, such as upgrades, application, or operating system patching. However, snapshots are not backups. AWS and the AWS Partner Network (APN) can help you with secure, efficient, and cost-effective backup and restore for VMware environments using products you know and trust.
Customers should ensure these backups are stored in different AWS Availability Zones or Regions depending on their individual requirements. Please refer to the following reference architecture for more details.
Disaster Recovery
The combination usually occurs in the event of natural disasters, but hardware failure or human error alone can trigger a disaster-level event. It’s imperative to have solid data protection strategy to achieve business continuity.
The requirement to maintain a physically separate disaster recovery (DR) site can be business or regulatory driven. Using VMware Site Recovery, you can eliminate the costs and efforts involved in operating a fully functioning DR site. It also allows companies to go from zero to ready for DR within hours using familiar technologies like VMware vSphere and VMware Site Recovery.
VMware Site Recovery is offered as a service, so that customers don’t have to take on the undifferentiated heavy lifting of software component interoperability and compatibility. You can simply go into the VMware Cloud on AWS portal and activate Site Recovery as an add-on.
Figure 5 – VMware Site Recovery between regions.
VMware Site Recovery provides an application-centric DR runbook that automates disaster recovery in an efficient way for customers. The service can be used in conjunction with your existing solutions that are based on VMware Site Recovery Manager, as well as vSphere Replication.
Customer Responsibility
For disaster recovery, it’s your responsibility to architect and implement an appropriate DR site for the workloads that need protection in the event of a disaster.
It’s recommended to choose your VMware Cloud Disaster Recovery site to be in a different region than your primary VMware Cloud on AWS SDDC, for protection from regional failures.
AWS Service Integration
For customers wishing to offload the management of filesystems to AWS, integration with AWS services is achieved through a high-bandwidth, low latency connectivity from SDDC through an elastic network interfaces (ENI) to a connected VPC in the customer’s account.
In addition, customers can make use of VPC endpoints. For customers using the ENI, VMware is responsible for the availability of this connectivity.
In addition to protecting their VMs, customers can leverage the native fully managed AWS services to run file servers within their VMware Cloud on AWS SDDC.
While Amazon S3 is ideal for applications that can access data as objects, many applications store and access data as files. Amazon Elastic File System (Amazon EFS) and Amazon FSx for Windows File Server are fully-managed AWS services that provide file-based storage for applications.
Customer Responsibility
It’s your responsibility to configure the firewall of the VMware Cloud on AWS SDDC to allow or disallow necessary traffic. You are also responsible to configure the connected VPC to allow and route traffic to and from your VMware Cloud on AWS SDDC.
When using Amazon EFS and FSx, you are responsible for moving their data to a different tier. You can configure AWS DataSync to perform data tiering and/or cross-regional protection to meet your regulatory and data protection requirements.
Reference Architecture
This architecture demonstrates best practices and considerations for VMware Cloud on AWS to optimize resiliency and high availability.
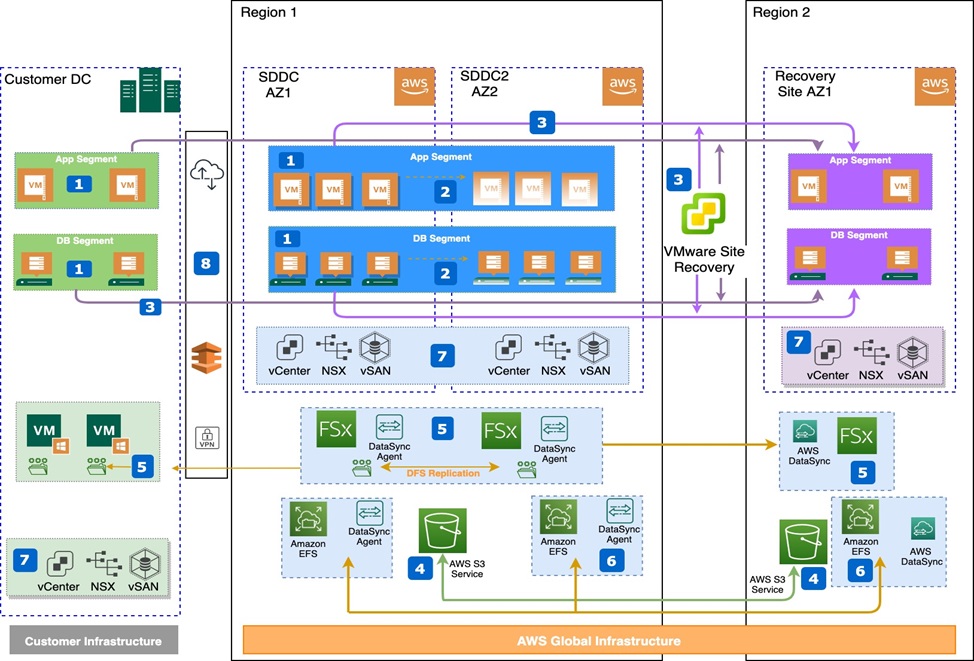
Figure 6 – Putting it all together.
Let’s look at the various components of this reference architecture:
- VMware HA will restart virtual machines on surviving hosts in the event of a host failure, providing site local resiliency. You should ensure you configure their vSAN policies to ensure you meet your site’s local performance and recovery requirements based on the amount of host failures their business will tolerate using a recommended policy of FTT2.
. - You should use VMware stretch clusters to protect VMs by restarting them on the remote site providing AWS Availability Zone resiliency within a region.
. - You can use VMware Site Recovery to protect on premises and/or VMware Cloud on AWS SDDC workloads between regions. VMware Site Recovery provides you with protection against regional disasters, and helps you meet your regulatory requirements.
. - Amazon S3 buckets are regional constructs, you can configure S3 to store backups in different regions to protect you from regional failures. This is not done by default, and you should ensure this is configured to meet regulatory and recovery requirements.
. - If you use Amazon FSx, you can configure this in the secondary (DR) region. You should configure an AWS DataSync agent near your source data, as well as the DataSync service to replicate data from the source to the DR region or Availability Zone.
. - You should also use AWS DataSync to copy data between Amazon EFS file systems, which should be placed in different regions and Availability Zones to ensure they can meet the recoverability requirements.
. - Changes to vCenter and NSX configurations are not saved until the next scheduled and completed backup. You are responsible to ensure these change details are captured in change logs, architecture diagrams, and internal change control processes. vSAN is not backed up, so you must ensure backups are configured, tested, and stored outside the SDDC.
. - You should have at least two virtual interfaces over separate physical AWS Direct Connect connections terminating at different Direct Connect locations for consistent performance while using VPNs as a backup.
Summary
VMware Cloud on AWS provides you with ways to protect your data using the built-in SDDC capabilities and leveraging AWS native services. You can use these to provide high levels of resiliency according to your application needs.
Existing and new customers must understand the architectural patterns and resiliency design considerations to avoid data loss and minimize downtime. We recommend you review the guidelines provided in this post and the reference architectures to help protect your applications, or contacting your dedicated AWS account team at aws-california-team@amazon.com.
